[논문리뷰] A ConvNet for the 2020s
- CVPR 2022
- Liu, Zhuang, et al. “A convnet for the 2020s.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . 2022.
Abstract
- 2020년 이후로 ViT 기반 모델들은 빠르게 발전되고 사용되고 있다. Swin Transformer 이후론 일반적인 비전 분야의 backbone으로 사용이 가능해지며, 넓은 범위에서 놀라운 성능보인다. 이후 Vision Task에 Transformer 연구가 집중되고 있다.
- 하지만 Transformer의 효율성은 convolution의 한계보다는 Transformer의 내재된 우월성으로 인한 것으로 본다. 이에 기존 CNN에서도 Transformer의 성능을 뛰어넘을 수 있음을 보이고자 한다.
- 본 논문에서는 CNN(ResNet base)에 최신 기법들을 적용하고, hierarchical Transformer 구조를 적용하였다. 그 결과로 만들어진 ConNeXt 모델은 ConvNet이 가지는 효율성과 심플함을 그래도 유지하면서도, 정확도와 scalability에서 Transformer와 맞먹는 성능을 보여주었다. 또한 Object Detection과 Segmentation에서도 좋은 성능을 보인다.
- 이를 통해 CNN이 여전히 강하다는 것을 주장하는 논문이다.

- 색 : 보라색은 CNN, 주황색은 Transformer 기반 Network
- 버블 크기 : 모델의 FLOPs
- 저자들이 제안한 ConvNeXt가 ImageNet-1K, 22K dataset 모두 현재 SOTA인 Swin Transformer의 accuracy를 조금 넘어서는 듯한 그래프를 확인할 수 있다.
Introduction
- CNN
- AlexNet(2012) 이후로 VGGNet, ResNe(X)t, DenseNet, MobileNet, EfficientNet, RegNet 등 수많은 논문들이 발표되며 점진적으로 발전되어 왔다.
- CNN은 Sliding Window를 통한 Inductive Bias를 통해 Image Recognition 분야에서 backbone network로 오랫동안 자리 잡아 왔다.
- Sliding Window는 영역 속 wieght를 공유하여 개체간의 관계가 약하고, 대신 특정 특징을 가지는 요소들이 공간적으로 서로 모여있는지 여부가 중요하다. 이로 인해 Inductive Bias(주어지지 않은 입력의 출력을 예측할 수 있는 일반화 성능)측면과 공간적 측면에서 이미지에서 강점을 보인다.
- Transformer
- NLP 분야는 Vision 분야와 다르게 RNN에서 Transformer로 급격하게 모델이 변화하였다.
- 2020년에서 ViT논문이 발표되며 Transformer가 Vision task까지 넘어오게 되었다. 이미지를 Patch 단위로 나누어 NLP의 단어처럼 표현하게 되었다.
- 2021년에 Swin Transformer 논문이 발표되며, Image task 전반에 Transformer가 적극 적용되고 SOTA를 달성하게 된다.
- block이 지날 수록 patch들을 merge 시켜나가는 Hierachical 구조와 patch들을 감싸는 window를 지정해 그 속 patch들간의 attention만 계산하는 구조를 제안한다.
- 이를 통해 기존 ViT에서 모든 패치 간의 attention을 구하느라 생기던 Quadratic Complexity 문제를 해결한다.
- 하지만 Swin Transformer의 한계들이 여전히 있다.
- CNN보다 비용이 많이든다.
- 속도 최적화를 위해선 설계가 정교해야한다.
- Window는 결국 CNN의 sliding window를 다시 가져온 것이다.
Modernizing a ConvNet : a Roadmap
- 논문에서는 FLOPs(4.5x10⁹)가 서로 비슷한 ResNet-50 / Swin-T(tiny)를 비교하면서 진행된다.

1. Traning Techniques
- ResNet-50에 다음과 같은 modern training techiques를 적용
- original 90 epochs → extended to 300 epochs
- AdamW optimizer
- Data Augmentation : Mixup, Cutmix, RandAugment, Random Erasing, regularization schemes including Stochastic Depth, Label Smoothing
- 그 결과 Accuracy가 76.1%에서 78.8%로 향상
2. Macro Design
- ResNet-50의 residual block 개수를 (3, 4, 6, 3) → (3, 3, 9, 3) 으로 변경
- Swin-T에서 1:1:3:1 비율로 Block이 실행되는 것을 따라함
- 정확도가 78.8% → 79.4%로 향상
- Block 개수가 늘어나 FLOPs도 4.1G에서 4.5G로 증가
- ResNet의 7x7 filer, stride 2, max pool로 4배 downsampling → 4x4 filter, stride 4로 Non-overplapping convolution
- Swin Transformer 가 4x4 patch로 이미지를 나누는 것을 따라함
- 정확도가 79.4% → 79.5%로 미세하게 상승
- FLOPs는 0.1G 감소
3. ResNeXt-ify
- ResNeXt 아이디어 : input channel을 32개의 patch로 나누어 각자 연산 후 다시 concat (grouped convolution)
- MobileNet 아이디어 : ResNeXt를 확장하여 channel 수만큼 group 나누기 (Depthwise convolution)
- ResNet에 MobileNet아이디어를 적용하여, FLOPs 대폭 축소. 이때 성능을 감소.
- Swin-T와 채널을 맞추기 위해, width를 64에서 96으로 증가시켜서, Accuracy 80.5% 달성, FLOPs 5.3% 달성.
4. Inverted Bottleneck
-
Bottleneck → Inverted Bottleneck 구조로 바꾸기
: 기존에 ResNeXt는 1x1 conv로 채널을 줄이고, 3x3 conv로 채널을 늘리기 → 채널을 늘리고, 줄이기
- MobilenetV2에서는 (b)와 같은 Inverted Bottleneck구조로 FLOPs 줄임
- Transformer도 사실상 Inverted Bottleneck 구조 사용되고 있음 (c구조)
- 이 결과 Accuracy 80.6%(0.1% up), 4.6G FLOPs(0.7 down)
-
Depthwise conv layer를 위로 이동 [ (b) → (c) ]
- Transformer에서 MSA(Multi head Self-Attention) Block 먼저 수행 후, MLP Block을 수행하는 구조를 따라하여, 좀 더 자연스러운 구조로 변환
- 그 결과 FLOPs 4.1G로 연산량은 감소해였지만, Accuracy는 79.9%로 감소하였다.

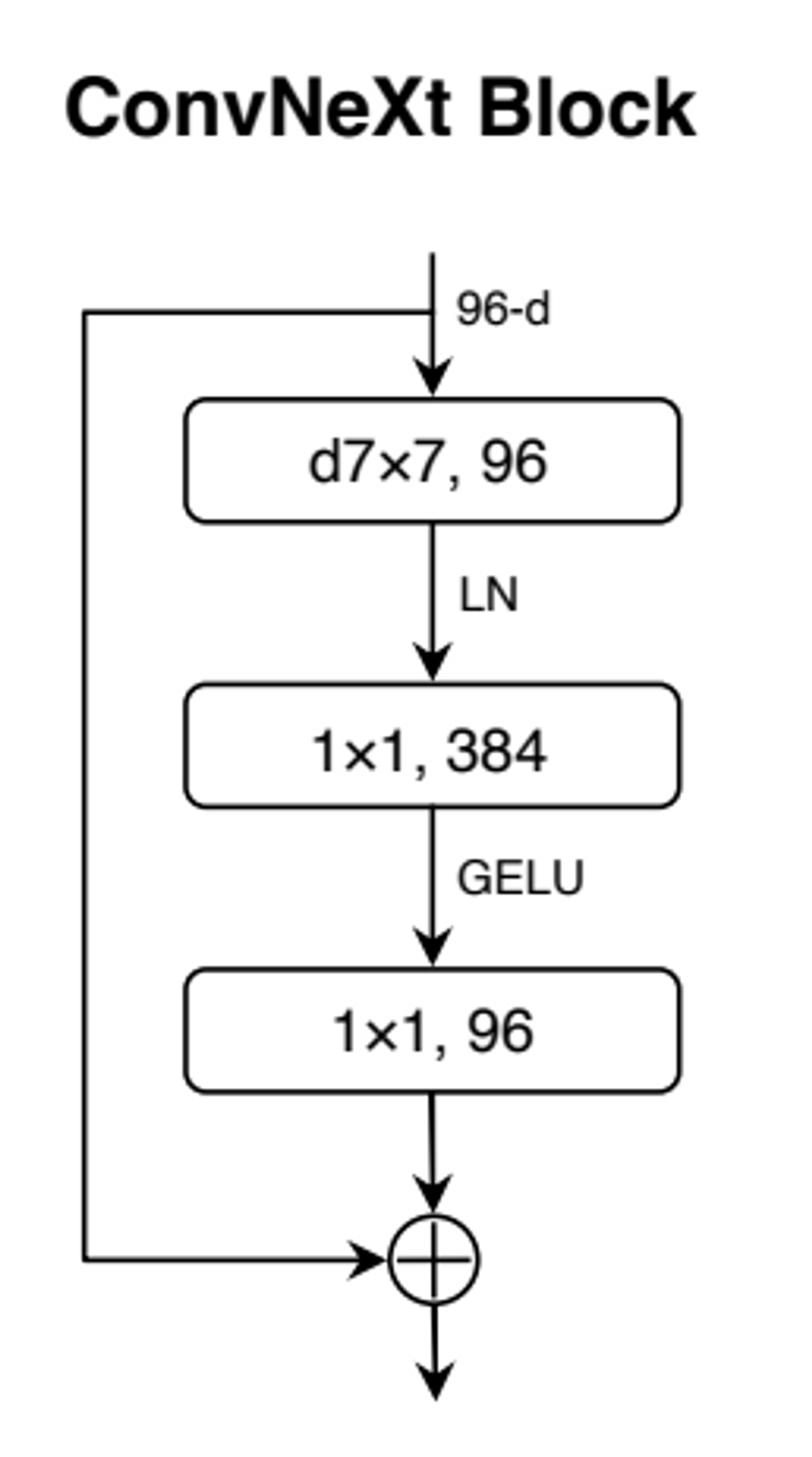
5. Large Kernel Sizes
- Kernel Size 3x3 → 7x7로 변경
- VGGNet이후로 연산량이 적어 layer를 더 쌓을 수 있는 3x3 conv를 대부분 모델에서 사용
- 하지만 Swin Transformer에서는 7x7 window size(49개 patch) 사용
- 이에 저자들은 3,5,7,9,11 kernel size 모두 실험하고, 그 결과 7x7이 가장 좋았다.
- FLOPs가 거의 유지된 상태로 정확도를 80.6%로 향상
6. Micro Design
- Activation function을 ReLU에서 GELU로 변경
- 처음엔 Transformer에서도 ReLU를 사용하였지만, BERT, GPT-2, ViT 등 최근 연구에선 Smoothing 버전인 GELU를 주로 사용
- 이로 인해 정확도랑 FLOPs가 변하진 않았지만, 저자들은 모든 activation function을 GELU를 사용
- Activation Function(GELU)을 1x1 conv 사이에 하나만 사용
- 일반적 ConvNet들은 conv→ normalization → activation이 공식화 되어 있음
- 하지만 Transformer는 MSA 부분에는 없고, MLP block에 단 한 개의 activation function만 사용. 이 구조를 따라함
- 그 결과 정확도 81.3%까지 상승
- Normalization도 한 번만 사용
- 한개의 BatchNorm을 inverted bottleneck의 첫번째 1x1 conv layer 앞쪽에 적용
- 81.4%(0.1% up)의 Accuracy를 보임.
- 여기까지 진행하였을 때 벌써 Swin-T의 81.3%를 넘음
- Batch Normalization 대신 Layer Normalization을 적용
- BN은 overfitting 방지 용으로 ConvNet에서 일반적으로 사용하지만, batch size에 다른 성능 변화 편차가 심한 등 성능에 악영향 주기도 함.
- Transformer는 LN을 좋은 성능
- LN을 ResNet에 바로 적용하면 오히려 성능 떨어짐
- 하지만 이미 많은 Mordern Tech 적용한 ConNeXt에서는 약간 상승(81.5%, 0.1% up)
- Downsampling layer 적용
- 높은 채널로 feature extraction 하기 위해, 기존 ResNet은 블럭의 첫 번재 layer를 3x3 conv, stride 2를 이용해 width와 height를 줄임
- Swin Transformer에선 이를 위한 추가적인 layer(down sampling layer)를 사용.
- ConNeXt에도 downsampling layer를 추가. 이때 학습 발산이 생겨서 normalization layer도 추가하여 안정시킴
- 정확도 82.0%까지 상승. FLOPs는 0.3G 증가
Result

참고자료
- 논문링크 : https://openaccess.thecvf.com/content/CVPR2022/papers/Liu_A_ConvNet_for_the_2020s_CVPR_2022_paper.pdf
- https://paperswithcode.com/paper/a-convnet-for-the-2020s
- https://blog.kubwa.co.kr/논문리뷰-a-convnet-for-the-2020s-9b45ac666d04
- https://kim95175.tistory.com/23
- https://re-code-cord.tistory.com/entry/Inductive-Bias란-무엇일까
- https://velog.io/@cgotjh/논문-리뷰-A-ConvNet-for-the-2020s
- https://engineering-ladder.tistory.com/73